限流器 (Rate Limiter)
- 文章發表於
前言
限流器(Rate Limiter)在当今的软件架构中扮演着不可或缺的角色。它能作为一道防护墙,防止软件服务遭到滥用或攻击,确保系统稳定性,同时保障所有用户的公平使用权益。
想象一家拥有破亿流量的软件服务商,像是 ChatGPT、x.com,如果没有限流器的保护,系统很可能被单一用户或恶意程序过度滥用,造成硬件资源被独占甚至崩溃,而影响到对其他用户的体验。使用限流器可以确保每位用户都能公平地使用资源,除了维持整体系统的效能稳定,并避免任何单一用户垄断资源或遭受到恶意攻击。
使用限流器的主要好处包括:
- 防止滥用:恶意用户可能试图通过大量请求(例如,DoS 攻击)或滥用 API(例如,人工灌水、过度抓取数据)来破坏系统的正常运作。
- 资源管理:确保后端服务不会因为大量请求而过载,进而维持系统的稳定性与可用性,让所有用户都能获得良好的使用体验。
- 公平使用:让所有用户都能公平地取得资源,避免少数高流量用户垄断资源,影响其他用户的服务质量。
- 成本控制:在云端环境中,过多的请求可能导致高昂的营运成本;通过限流机制(Rate Limiting),可以有效控制并管理这些成本。
流程概述
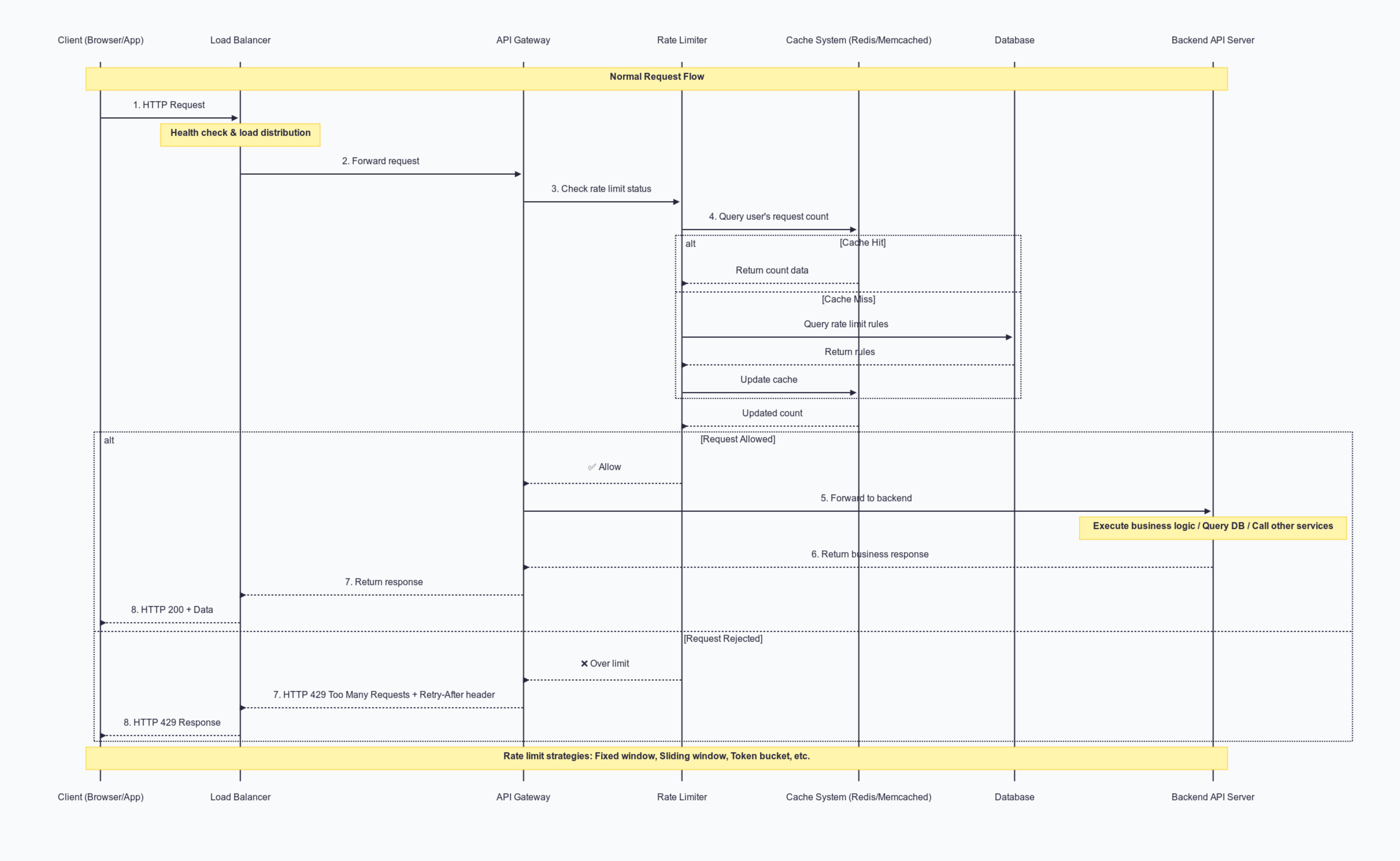
使用限流器后,整体的用户流程就如下:
- 客户端发送请求 用户(通过浏览器或移动应用)发送一个 HTTP 请求。
- 负载平衡器接收请求 负载平衡器负责执行健康检查,并将请求分配至可用的 API Gateway 节点。
- API Gateway 转发至限流器 API Gateway 在进行任何后端处理前,会将请求传送至限流器。
- 限流器检查使用数据 限流器查询缓存系统(例如 Redis 或 Memcached),以取得该用户当前的请求次数。若缓存中没有数据,可能会查询数据库以获取限流规则,并更新缓存。
- 判断:允许或拒绝
- 允许 – 限流器通知 API Gateway 继续处理请求。
- 拒绝 – 限流器通知 API Gateway 立即回传 HTTP 429 Too Many Requests 错误,并可选择附加
Retry-After标头,告知客户端多久后可以再次尝试。
- 转发至后端 API(若允许) API Gateway 将请求转发至后端 API 服务器,执行业务逻辑、查询数据库或调用其他服务。
- 将响应返回给客户端 API 响应会通过 API Gateway 和负载平衡器返回给客户端。
本篇文章将会着重在如何实现限流器常见的算法,并实现一个简单的限流器。
实现
如同在先前的限流器探讨中所提及,设计一个限流器的核心目的,无非是为了防止单一用户滥用资源、应对恶意攻击,并同时兼顾成本控制。然而,该如何将这些概念实际地落实到代码中呢?
在真正动手实现之前,不妨先思考一下:我们需要哪些元素,以及应该回传什么信息?
举例来说,有使用过 Claude 或是 ChatGPT 的读者应该多少都有被限流的经验,当你使用量超标时就会看到界面上显示 "您已超过使用上限,请在几点后再试",或是快超标时就会显示 "您的请求次数剩余 X 次,下次更新时间为 Y 日" 的讯息。
要有上述的效果,后端会需要用 HTTP 状态码(例如 429 Too Many Requests)配合 Header(如 X-RateLimit-Limit、X-RateLimit-Remaining、X-RateLimit-Reset 或 Retry-After)来告知客户端该用户是否被限流与剩余额度。客户端只要侦测到状态码或读取相关 Header,就能正确呈现相对应的讯息告知用户。
而一个理想的限流响应应该包含以下字段:
{success: boolean, // 是否允许此次请求继续执行limit: number, // 当前时间窗口内允许的最大请求数remaining: number, // 剩余可用的请求次数reset: number, // 当前时间窗口重置的时间点(Unix timestamp)pending: Promise // 背景处理任务(例如数据同步或缓存清理)}
如此一来,客户端可以根据这个统一的数据结构,判断是否需要显示提示讯息,或者在必要时自动排程重试。
基本架构
限流器的基本功能通常包含:设定特定期间内的请求上限、选择限流算法,以及自定义存储空间。我们将通过 Strategy Pattern 让使用套件的开发者自行指定所要使用的算法。
我们将会介绍以下几种常见的限流算法:
- 固定窗口 (Fixed Window)
- 滑动窗口 (Sliding Window Log)
- 滑动窗口计数 (Sliding Window Count)
- 令牌桶 (Token Bucket)
实现框架
/*** 用于应用速率限制的主要类别。* 使用策略模式,允许在执行时传入不同的限流算法。*/class RateLimit {/*** @param {object} config - 限流器的设定对象。* @param {function} config.limiter - 特定的限流算法函数 (由静态方法之一产生)。* @param {RedisMap} [config.storage] - (可选) 用于存储状态的实例,预设为新的 RedisMap。* @param {number} [config.delay] - (可选) 用于模拟网络延迟的毫秒数。*/constructor(config) {this.limiter = config.limiter;this.storage = config.storage || new RedisMap();this.delay = config.delay || 10; // 预设模拟延迟}/*** 对给定的识别符应用已设定的速率限制。* @param {string} identifier - 用于区分被限制实体的唯一识别符 (例如,用户 ID、IP 地址)。* @returns {Promise<object>} 一个 Promise,其解析值为一个对象,包含成功/失败及限制详情。* @example* const result = await rateLimiter.limit("user-123");* // result: { success: boolean, limit: number, remaining: number, reset: number }*/async limit(identifier) {return await this.limiter(this.storage, identifier, this.delay);}/*** 在固定的、不重叠的时间窗口内限制请求。* @param {number} tokens - 每个窗口内允许的最大请求数。* @param {string} window - 时间窗口的持续时间 (例如 "60s", "1m")。* @returns {function} 限流器函数,可传入 RateLimit 的建构子。*/static fixedWindow(tokens, window) {const windowDuration = parseWindow(window);return async (storage, identifier, delay) => {// 算法实现...};}/*** 通过加权计算当前和前一个固定窗口来近似一个滑动窗口。* @param {number} tokens - 每个窗口内允许的最大请求数。* @param {string} window - 时间窗口的持续时间 (例如 "60s", "1m")。* @returns {function} 限流器函数。*/static slidingWindow(tokens, window) {const windowDuration = parseWindow(window);return async (storage, identifier, delay) => {// 算法实现...};}/*** 允许突发请求,最高可达桶的容量,并以固定速率补充令牌。* @param {number} refillRate - 每个间隔时间补充的令牌数量。* @param {string} interval - 补充令牌的间隔时间 (例如 "1s", "10s")。* @param {number} maxTokens - 桶能容纳的最大令牌数。* @returns {function} 限流器函数。*/static tokenBucket(refillRate, interval, maxTokens) {return async (storage, identifier, delay) => {// 算法实现...};}/*** 维护一个在滑动窗口内请求的时间戳日志。* @param {number} tokens - 每个窗口内允许的最大请求数。* @param {string} window - 时间窗口的持续时间 (例如 "60s", "1m")。* @returns {function} 限流器函数。*/static slidingWindowLog(tokens, window) {return async (storage, identifier, delay) => {// 算法实现...};}}
固定窗口 (Fixed Window)
固定窗口顾名思义就是将时间划分为固定长度的「时间窗口」(例如每分钟、每小时),并在每个窗口内追踪、累计收到的请求数量。当一个时间窗口结束,进入下一个新的窗口时,前一个窗口的计数器便会自动重置为零。
整体流程说明如下:
- 我们会接受到两个参数:
tokens:在这个时间窗口内,允许的最大请求数量。window:窗口长度(毫秒),例如 1m(代表一分钟)。
- 计算当前请求所属的 bucket
- 将
identifier(例如用户 ID、API 密钥)与 bucket 结合成唯一 key,向存储空间 (Redis/Memcached) 读取目前已记录的请求数。 - 判断是否超过配额
- 如果目前已累计的请求数量 ≥ tokens,表示配额已满,必须拒绝本次请求。
- 如果目前累计的请求数量 < tokens,代表还能允许更多请求,就将该 bucket 的计数加一,并回传成功讯息。
- 自动重置
当进入下一个新的 bucket 后,旧的 bucket 编号自然被淘汰,其对应的计数器也不再使用;新 bucket 的计数器会从零开始累计。
上述大多数只是取值判断是否要拒绝或接受请求,再来就是更新值,最具挑战性的地方在于:如何在不存储每个请求的时间戳(timestamps)前提下,仍能高效地追踪「在特定时间窗口内的请求数量」?
const bucket = Math.floor(Date.now() / windowDuration);
这样我们就不需要去存储每个请求的时间戳,而是可以通过计算当前时间与窗口长度来得到当前请求所属的 bucket。
同时这样做的好处是:
- 全域一致性:同一时间区间内的所有请求都落在相同的 bucket。
- 自动过期:当 bucket 编号向前推进后,过去的 bucket 自然而然就不再被使用。
O(1)操作:无需扫描整个时间戳数组,只要直接计算 bucket 编号即可
class RateLimit {...static fixedWindow(tokens, window) {const windowDuration = parseWindow(window);return async (storage, identifier, delay) => {// 1. 计算目前请求所属的 bucketconst currentBucket = Math.floor(now / windowDuration);const key = `${identifier}:${currentBucket}`// 2. 读取此 bucket 已使用的 tokens(若不存在就视为 0)const previousTokens = storage.get(key) || 0;const reset = (currentBucket + 1) * windowDuration;// 3. 如果已经用满,就拒绝if (previousTokens > tokens) {return { success: false, remaining: 0, limit: tokens, reset }}// 4. 尚未超过,累加并更新存储空间const currentTokens = previousTokens + 1;// 5. 如果是此 bucket 第一次被写入,设定过期时间if (currentTokens === 1) {storage.pexpire(key, Math.floor(windowDuration * 1.5))}storage.set(key, currentTokens)return { success: true, limit: tokens, remaining: tokens - currentTokens, reset }};}...}
优点:
- 实现简单: 逻辑清晰,易于理解和实现。
- 内存效率高: 只需要为每个受限制的实体 (如用户 ID 或 IP 地址) 在当前时间窗口内维护一个计数器。
- 计算开销小: 计数和重置操作通常很快。
缺点:
- 窗口边界效应 (Window Boundary Effect) / 临界区问题:
这是此算法最主要的缺陷。在时间窗口的边界处,流量的实际速率可能超过设定的平均速率。例如,若限制为每分钟 100 次请求,用户可以在 0:00:59 时刻发送 100 次请求 (被允许),紧接着在 0:01:00 时刻 (新窗口开始) 再发送 100 次请求 (也被允许)。这导致在短短的几秒钟内,系统实际处理了 200 次请求,可能会对后端服务造成冲击。 - 流量不平滑: 由于计数器在每个窗口开始时重置,可能会导致流量在窗口初期集中爆发。
滑动窗口 (Sliding Window Log)
滑动窗口旨在解决固定窗口的缺点,它允许在窗口边界处的流量平滑过渡,避免流量在窗口开始时突然爆发。其会记录每个请求到达的时间戳。当一个新请求到达时,系统会检查在过去一个「滑动时间窗口」(例如过去 60 秒) 内的所有请求时间戳。如果这些时间戳的数量超过了预设的阈值,则拒绝新请求。
class RateLimit {...static slidingWindow(tokens, window) {const windowDuration = parseWindow(window);return async (storage, identifier, delay) => {const now = Date.now();const key = `log:${identifier}`;// 1. 取出存储的时间戳数组,若不存在就用空数组let timestamps = storage.get(key) || [];// 2. 过滤掉「窗口外」(<= now - windowDuration) 的时间戳const windowStartTime = now - windowDuration;timestamps = timestamps.filter(ts => ts > windowStartTime);// 3. 如果在这个窗口已有 tokens 笔请求,就拒绝// earliest = timestamps[0]if (timestamps.length >= tokens) {// 计算下一次可用的时间:earliestTimestamp + windowDurationconst resetTime = timestamps[0] + windowDuration;// 把「过滤后的数组」存回去,并设定 TTLstorage.set(key, timestamps);// 多加 1000 毫秒 (1 秒) 是为了保证 key 不会因为极端情况(如网络延迟、程序执行时间)过早过期,确保所有在窗口内的请求都能被正确统计。storage.pexpire(key, windowDuration + 1000);return {success: false,limit: tokens,remaining: 0,reset: resetTime};}// 4. 还没到上限,就把 now 推进去,并存回去timestamps.push(now);storage.set(key, timestamps);storage.pexpire(key, windowDuration + 1000);// 5. 计算剩余额度与重置时间const remaining = tokens - timestamps.length;// 重新算 earliestTimestamp + windowDuration 作为 resetconst reset = timestamps[0] + windowDuration;// 6. FOR DEV PURPOSE, 如果要模拟 background work,就用 delayif (delay) {await new Promise(resolve => setTimeout(resolve, delay));}return {success: true,limit: tokens,remaining,reset};};}...}
优点:
- 精确的流量控制: 能够非常精确地限制在任何给定时间段内的请求数量,有效避免了固定窗口的边界效应。
- 流量平滑: 由于窗口是连续滑动的,流量控制更为平滑。
缺点:
- 内存消耗大: 需要存储每个请求的时间戳,当请求量很大时,内存开销会非常显著。
- 计算成本高: 每次请求都需要对时间戳列表进行清理和计数操作,尤其是在高并发情况下,这些操作可能成为效能瓶颈。
滑动窗口计数 (Sliding Window Count)
滑动窗口计数 旨在结合固定窗口计数器的低内存消耗和滑动窗口日志的平滑流量控制特性。它通过维护当前时间窗口和前一个时间窗口的请求计数,并根据当前时间在窗口中的位置,加权计算一个近似的滑动窗口内的请求总数。
整体流程说明如下:
- 时间分片与计数器: 与固定窗口类似,时间被划分为固定长度的窗口,并为每个窗口维护计数器。
- 近似滑动计数: 当一个新请求到达时,它不仅考虑当前窗口 (currentWindowCount) 的请求数,还会考虑前一个窗口 (previousWindowCount) 的请求数。
- 近似总数 = (previousWindowCount * 重叠比例) + currentWindowCount
- 其中,「重叠比例」指的是前一个窗口有多少部分依然落在当前的「滑动窗口」内。例如,如果窗口大小是 60 秒,当前时间是 1:00:15 (即当前窗口已过 15 秒),那么前一个窗口 (0:59:00-1:00:00) 有 45 秒 (即 75%) 的内容依然在过去 60 秒的滑动窗口内。
- 限制检查: 如果这个近似总数小于阈值,则允许请求,并增加当前窗口的计数器;否则拒绝。
范例说明(假设限制为每 60 秒最多 100 个请求,窗口长度为 60 秒):
- 窗口 1(0:00:00 - 0:01:00):共收到 80 个请求,
count_window1 = 80 - 窗口 2(0:01:00 - 0:02:00):
- 在 0:01:15(当前窗口已过 15 秒,占 25%)时:
- 前一窗口的贡献比例 = (60 - 15) / 60 = 45 / 60 = 75%
- 假设此时窗口 2 已有 10 个请求(
count_window2 = 10) - 近似滑动总数 = (count_window1 × 75%) + count_window2 = (80 × 0.75) + 10 = 60 + 10 = 70
- 70 < 100,请求允许
- 在 0:01:45(当前窗口已过 45 秒,占 75%)时:
- 前一窗口的贡献比例 = (60 - 45) / 60 = 15 / 60 = 25%
- 假设此时窗口 2 已有 50 个请求(
count_window2 = 50) - 近似滑动总数 = (count_window1 × 25%) + count_window2 = (80 × 0.25) + 50 = 20 + 50 = 70
- 70 < 100,请求允许
- 在 0:01:15(当前窗口已过 15 秒,占 25%)时:
class RateLimit {...static slidingWindow(tokens, window) {const windowDuration = parseWindow(window);return async (storage, identifier, delay) => {const now = Date.now();// 1. 计算「当前」与「上一个」bucketconst currentBucket = Math.floor(now / windowDuration);const previousBucket = currentBucket - 1;const currentKey = `${identifier}:${currentBucket}`;const previousKey = `${identifier}:${previousBucket}`;// 2. 取得各 bucket 的 token 数(预设为 0)const currentTokens = storage.get(currentKey) || 0;const previousTokens = storage.get(previousKey) || 0;// 3. 计算上一个 bucket 的加权 token 数const elapsed = now % windowDuration;const overlapRatio = 1 - (elapsed / windowDuration);const weightedPrevious = Math.floor(previousTokens * overlapRatio);// 4. 计算滑动窗口内的总 token 数const totalTokens = currentTokens + weightedPrevious;const reset = (currentBucket + 1) * windowDuration;// 5. 检查是否超过配额if (totalTokens >= tokens) {return {success: false,limit: tokens,remaining: 0,reset};}// 6. 尚未超过,累加当前 bucket 的 token 并更新 storageconst newCurrentTokens = currentTokens + 1;storage.set(currentKey, newCurrentTokens);// 7. 若是第一次写入,设定 TTLif (newCurrentTokens === 1) {// TTL 设为 windowDuration * 2 + 1000,确保前一个 bucket 尚未过期storage.pexpire(currentKey, Math.floor(windowDuration * 2 + 1000));}// 8. 计算新的剩余次数const newTotalTokens = newCurrentTokens + weightedPrevious;const remaining = Math.max(0, tokens - newTotalTokens);// 9. FOR DEV PURPOSE, 模拟背景延迟if (delay) {await new Promise(resolve => setTimeout(resolve, delay));}// 10. 回传成功讯息return {success: true,limit: tokens,remaining,reset};};}}
优点:
- 流量平滑:与固定窗口计数法相比,滑动窗口计数能有效减少窗口边界带来的突发流量,使限流效果更平滑。
- 内存效率高:仅需存储当前与前一个窗口的计数,所需内存远低于滑动窗口日志法。
- 实现难度适中:比滑动窗口日志简单,仅稍微复杂于固定窗口计数。
缺点:
- 仅为近似值:无法像滑动窗口日志法那样做到完全精确,遇到极端流量分布时可能有误差。
- 需精确计算重叠比例:必须正确计算窗口重叠比例,并妥善维护两个窗口的计数。
令牌桶 (Token Bucket)
令牌桶的概念就是将每个请求想象成从一个「令牌桶」中获取令牌。系统会以恒定的速率向这个桶中添加令牌。每个进入系统的请求都必须先从桶中获取一个令牌才能被处理。如果桶中有足够的令牌,请求会被立即处理;如果桶中令牌不足,请求则会被拒绝、排队等待,或采取其他降级策略。
class RateLimit {...static tokenBucket(refillRate, interval, maxTokens) {const intervalDuration = parseWindow(interval);return async (storage, identifier, delay) => {const now = Date.now();const key = `token:${identifier}`;// 1. 取得现有 bucket 状态,预设为满桶let bucketData = storage.get(key) || {tokens: maxTokens,lastRefillAt: now,};// 2. 计算距离上次 refill 经过的时间const timePassed = now - bucketData.lastRefillAt;// 3. 计算应该 refill 几次const refills = Math.floor(timePassed / intervalDuration);// 4. 根据 refill 次数补充 tokenlet currentTokens = bucketData.tokens;let newLastRefillAt = bucketData.lastRefillAt;if (refills > 0) {currentTokens = Math.min(maxTokens,bucketData.tokens + refills * refillRate);newLastRefillAt = bucketData.lastRefillAt + refills * intervalDuration;}// 5. 若 token 不足,拒绝请求,计算下次可用时间if (currentTokens < 1) {const timeSinceLastRefill = now - newLastRefillAt;const timeToNextRefill = intervalDuration - (timeSinceLastRefill % intervalDuration);const reset = now + timeToNextRefill;storage.set(key, {tokens: currentTokens,lastRefillAt: newLastRefillAt,});storage.pexpire(key, Math.max(intervalDuration * 5, parseWindow("1h")));return {success: false,limit: maxTokens,remaining: 0,reset,};}// 6. token 足够,消耗 1 个const tokensLeft = currentTokens - 1;storage.set(key, {tokens: tokensLeft,lastRefillAt: newLastRefillAt,});storage.pexpire(key, Math.max(intervalDuration * 5, parseWindow("1h")));// 7. 模拟延迟if (delay) {await new Promise(resolve => setTimeout(resolve, delay));}// 8. 计算下次 refill 时间let reset;if (tokensLeft < maxTokens) {const timeSinceLastRefill = now - newLastRefillAt;const timeToNextRefill = intervalDuration - (timeSinceLastRefill % intervalDuration);reset = now + timeToNextRefill;} else {reset = now;}return {success: true,limit: maxTokens,remaining: tokensLeft,reset,};};}}
各算法比较

